Mick Lévy est directeur de l’innovation business chez Business & Décision. Il conseille depuis 20 ans des entreprises de multiples secteurs sur leur stratégie de valorisation des données. Auteur du livre «Sortez vos données du frigo», paru aux éditions Dunod en Février dernier, il est le grand témoin de l’édition 2021 d’Intelligence Marketing Day. Dans un entretien réalisé par BDM, Mick Lévy aborde l’importance des nouveaux usages de la data et de l’intelligence artificielle dans l’écosystème des entreprises. Et si toutes les données disponibles dans votre entreprise n’étaient pas exploitées ?
Votre livre est un manifeste pour une exploitation intensive et responsable des données et de l’intelligence artificielle. Qu’entendez-vous par là ?
Toutes les entreprises ont des données qui dorment dans les frigos informationnels de l’entreprise, dans leurs bases de données. Trop peu les considèrent encore comme un actif. Et c’est vrai pour toutes les entreprises, de toutes tailles et de tous secteurs ! Elles ont toutes des données qui sont uniques mais pourtant peu ou pas exploitées. La première partie du manifeste repose donc sur une incitation à utiliser l’intelligence artificielle pour le faire.
La seconde assume que les données donnent de grands pouvoirs et impliquent donc de grandes responsabilités. Cela comprend bien sûr les sujets autour de la protection des données, dont on entend déjà parler depuis quelques décennies, mais qui prennent une toute autre importance avec l’intelligence artificielle, qui ajoute une notion d’éthique au débat.

Les deux sujets sont-ils liés ?
On ne peut pas avoir une utilisation intensive des données si on ne sait pas exactement celles dont on dispose. C’est le tout premier sujet : comment quantifier et cartographier le patrimoine des données de mon entreprise ? On sait généralement quantifier de nombreuses choses qui ne délivrent pas de valeur. Pourtant, avoir une vision de cet actif et de ce qu’il peut valoir en termes d’usage est souvent complexe. Pour avoir une utilisation maîtrisée, éthique mais également intensive, et ainsi dégager de la valeur, la toute première des choses est donc de s’intéresser à ce patrimoine et de mieux le connaitre.
Comment mettre en place les conditions de cette utilisation intensive et responsable ?
Il faut bien sûr commencer par s’intéresser aux données dont on dispose ou qui peuvent être à notre portée (telles que les données open data, les données de partenaires ou d’entreprises avec lesquelles on travaille, par exemple). Pour les données internes, il existe des outils qui permettent d’automatiser le recensement si on le souhaite.
Il faut également s’intéresser aux processus de l’entreprise, à la manière dont sont collectées les données, où elles sont stockées. C’est d’ailleurs une obligation réglementaire pour certaines typologies de données telles que les données à caractère personnel avec le RGPD. Ensuite, il faut réfléchir à ce que l’on peut faire de ces données et de leur exploitation. Pour cela, il est important de s’intéresser aux cas d’usage. Dans le cas du marketing, cela concerne par exemple l’amélioration de la connaissance clients, notamment grâce aux capacités prédictives de l’IA. A quels produits pourrait-il s’intéresser ? Quand risque-t-il de quitter l’entreprise et de résilier ses contrats ?
Cela va concerner aussi l’expérience client et sa personnalisation, les moteurs de recommandation, avec à la clé une amélioration du ROI et des processus du service marketing. Sans oublier le social listening, qui consiste à écouter les tendances mais aussi ses clients sur les réseaux sociaux. Ce sont des cas d’usage assez classiques dans le domaine du marketing qui promettent de très beaux retours sur investissement.
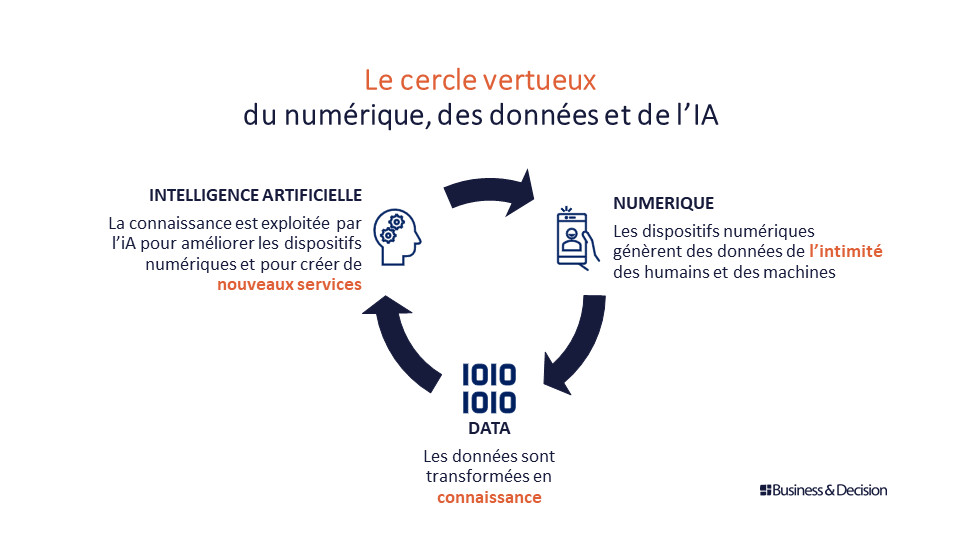
Quels types d’entreprises et quels types de professionnels sont concernés ?
Personne ne peut s’en passer, d’un point de vue réglementaire pour commencer. Le RGPD oblige les entreprises à avoir une meilleure maîtrise des données personnelles des clients et des collaborateurs, notamment. Ensuite, toutes les entreprises vont avoir des problématiques différentes face aux données. Une entreprise industrielle s’intéressera potentiellement aux données de ses moyens de production, aux données de ses machines et les capteurs vont permettre de ramener énormément d’informations pour travailler sur des schémas de maintenance prédictive, par exemple, ou de personnalisation des produits. Une entreprise de services ou de retail va beaucoup plus s’intéresser à ses données client, à ses ventes, etc. La nature des données et ce que l’on va pouvoir en faire va changer en fonction du type d’entreprise.
Une différence va également se faire en fonction de la taille de l’entreprise, sous la forme d’une approche build or buy. Une grande entreprise va avoir tendance à elle-même construire ses infrastructures, ses pipelines de données, ses bases de données, ses moyens d’exploitation et ses algorithmes d’IA, quand une petite structure pourra acheter des solutions sur étagère, éventuellement déjà intégrées à un CRM, par exemple, qui vont valoriser les données de manière plus automatique.
Existe-t-il un risque de devenir dépendant des fonctionnalités des outils que l’on utilise et de leurs limites ?
Cela va dépendre des choix de l’entreprise et de ses capacités d’investissement. Valoriser un actif comme celui de la data, comme tout autre actif, a des coûts et nécessite des choix de priorisation budgétaire. Les entreprises qui auront fait le choix du mode « buy » vont profiter de nouvelles fonctionnalités mises à disposition par l’éditeur de leur logiciel ou intégrée directement dans leur progiciel métier. Mais cela ne permet pas de prendre un avantage concurrentiel car elle est proposée à tous les utilisateurs de cet outil.
Les entreprises qui voudront exploiter plus intensément les données, qui voudront mettre plus de priorités dans l’exploitation de cet actif auront effectivement intérêt à développer elles-mêmes leur propre chaîne de traitement et leurs propres algorithmes, parce que cela va constituer un élément différenciant pour prendre un avantage concurrentiel sur le marché.

A lire également : Marketing & Sales : comment bien coordonner le partage de la data ?
Quelles sont les compétences et métiers dont les entreprises vont avoir besoin dans ce domaine ?
On a beaucoup parlé de la compétence du data scientist mais il ne peut pas tout faire tout seul. Assembler un ensemble de compétences est nécessaire : le data scientist sur le volet algorithmique, le data engineer pour récolter des données, croiser les données et mettre en place le data pipeline et les bases de données et puis aussi des compétences côté métier extrêmement importantes comme le data analyst qui a une forte connaissance du business, des règles de gestion et des données pour pouvoir correctement les exploiter.
Il est important de mettre en place une organisation centrée sur un chief data officer, éventuellement, avec toutes les fonctions qui vont permettre d’exploiter les données de l’entreprise. Il faut également mettre en place les outils et processus qui vont permettre de développer la gouvernance des données. Bref, exploiter les données est un véritable chemin de transformation qui implique toute l’entreprise, non seulement sur le volet technologique mais aussi sur les volets organisationnels et processus.
Concernant l’aspect éthique, comment faire en sorte que les obligations réglementaires (notamment le RGPD) ne soient pas un frein, mais une opportunité ?
Personnellement, je suis un grand défenseur du RGPD. Je suis convaincu qu’en réalité, il a permis de faire avancer la cause des entreprises sur l’exploitation de leurs données, parce que du jour au lendemain, elles ont été obligées de très fortement s’intéresser aux données clients. Se mettre en conformité leur a aussi servi à se rendre compte de ce potentiel. De plus, on constate un niveau d’engagement accru des clients qui ont donné leur consentement.
Il y a ensuite une question de posture du DPO. Il ne faut pas qu’il se positionne en barrière, en frein, mais plutôt en partenaire des projets, en disant aux porteurs de projets : « Dis-moi ce que t’as envie de faire avec les données et on va trouver ensemble les moyens juridiques, légaux et techniques d’y parvenir tout en respectant la réglementation. » Par ailleurs, la Commission européenne a annoncé un nouveau projet de règlementation sur l’éthique de l’IA. Ce sujet de l’éthique va donc continuer à être central. Il est important qu’il soit abordé par les entreprises dès maintenant.
Le livre de Mick Levy, « Sortez vos données du frigo » est disponible aux éditions Dunod. Retrouvez les actualités de Mick Levy sur Twitter et LinkedIn ainsi que ses publications sur le blog de Business & Decision.
Revivez la conférence de Mick Lévy lors de l'événement IMD21 !
(Re)découvrez la conférence du grand témoin de cette 4e édition qui aborde l'usage des données et leur transformation avec le big data et l'intelligence artificielle !